트랜잭션 특징과 격리 수준
트랜잭션
트랜잭션(Transaction) 은 데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위이다.
[트랜잭션이 필요한 예시]
A 가 B 에게 계좌이치를 하는 상황을 생각해보자.
1. A 의 계좌에서 돈을 꺼낸다.
2. B 의 계좌에 돈을 넣는다.
위의 두 작업은 함께 이루어지거나 혹은 둘 다 이루어지면 안된다.
만약 A 계좌에서 돈을 꺼냈는데 시스템상 오류로 B 계좌에 돈이 들어오지 않는다는 큰 문제가 생겨서는 안된다.
이를 위해 트랜잭션은 Commit 과 Rollback 을 지원한다.
- commit : 모든 부분 작업이 정상적으로 완료되면 이 변경사항을 한번에 DB에 반영한다.
- rollback : 부분 작업에 실패하면 모든 부분 작업을 실행 전 상태로 되돌린다.
트랜잭션 특징 (ACID)
- 원자성 (Atomicity)
- 트랜잭션은 원자적인 단위로 간주된다.
- 즉, 트랜잭셔은 DB에 모두 반영되거나 전혀 반영되지 않아야 한다. (All or Nothing)
- 일관성 (Consetency)
- 트랜잭션이 실행된 후에 데이터베이스가 언제나 일관된 상태를 유지해야 한다.
- 트랜잭션이 데이터베이스에 어떤 변경을 가하더라도, 데이터베이스는 미리 정의된 규칙에 따라 일관성을 유지해야 한다.
- 예시) A 계좌와 B 계좌의 합계가 100만원이면, 트랜잭션이 실행된 후에도 합계는 여전히 100만원이어야 한다.
- 격리성 (Isolation)
- 트랜잭션 수행 시 다른 트랜잭션의 작업이 끼어들지 못하도록 보장해야 한다.
- 둘 이상의 트랜잭션이 병행 실행되고 있을 때, 어떤 트랜잭션도 다른 트랜잭션 연산에 끼어들 수 없다.
- Locking 을 통해 해결할 수 있다.
- 영속성 (Durability)
- 트랜잭션이 성공적으로 완료된 후에는 그 결과가 영구적으로 저장되어야 한다.
- 시스템이 고장 나거나 중단되더라도 트랜잭션이 성공적으로 완료된 데이터는 손상되지 않아야 한다.
트랜잭션의 격리 수준 (Isolation level)
트랜잭션의 격리 수준이란 여러 트랜잭셔이 동시에 처리될 때 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 볼 수 있게 허용할지 말지를 결정하는 것이다.
READ UNCOMMITED, READ COMMITED, REPEATABLE READ, SERIALIZABLE 4 가지로 나뉜다.
뒤로 갈수록 트랜잭션 간의 데이터 격리 정도가 높아지며 동시 처리 성능은 낮아진다.
READ UNCOMMITED 은 일반적인 데이터베이스에서 거의 사용하지 않고 SERIALIZABLE 또한 동시성이 중요한 데이터베이스에서 거의 사용하지 않는다.

- DIRTY READ
- 한 트랜잭션이 아직 commit 되지 않은 다른 트랜잭션의 변경된 데이터를 읽는 현상.
- NON-REPEATABLE READ
- 한 트랜잭션이 같은 쿼리를 두 번 실행했을 때, 그 사이에 다른 트랜잭션의 변경으로 인해 결과가 다르게 나타나는 현상. (데이터의 내용이 변경되는 것에 중점)
- PHANTOM READ
- 한 트랜잭션이 같은 쿼리를 두 번 실행했을 때, 그 사이에 다른 트랜잭션의 삽입 또는 삭제로 인해 결과가 다르게 나타나는 현상. (데이터의 개수가 변경되는 것에 중점)
READ UNCOMMITED

사용자 A 가 테이블에 새로운 데이터를 삽입하고 해당 내용을 커밋하기 전에 사용자 B 가 해당 내용을 조회하고 있다.
만약 사용자 A 의 삽입 작업이 처리도중 롤백 된다면 사용자 B 는 이 사실을 모르고 잘못된 정보를 사용할 것이다.
이런 상황을 DIERTY READ 라고 한다.
READ UNCOMMITTED 는 이런 DIERTY READ 를 허용하기 때문에,
MySQL 에서는 최소 READ COMMITTED 이상의 격리 수준 사용을 권고한다.
READ COMMITTED
READ COMMITTED 는 DIERTY READ 를 허용하지 않는다.
아래 그림 예제를 통해 어떻게 허용하지 않는 지 살펴보자.

사용자 A 가 500000 번 레코드의 이름을 Lara -> Toto 로 변경하였다.
이때 실제 테이블의 내용이 변경 되고 변경 전 데이터는 언두 로그에 복사해둔다.
만약 사용자 B 가 변경된 내요이 커밋되기 전에 500000번 레코드를 조회한다면 이때는 언두 로그에 백업된 레코드인 'Lara' 를 조회한다.
하지만 READ COMMITTED 격리 수준에서도 NON-REPEATABLE READ 가 발생한다

사용자 B 가 테이블에서 처음 Toto 를 검색했을 때는 검색 결과가 없었고
사용자 A 가 Lara -> Toto 로 업데이트 후 다시 검색했을 때는 검색 결과가 생겼다.
크게 문제 될 거 없어 보일 수 있지만 사용자 B 의 같은 select 연산이 같은 트랜잭션 안에서 일어났다는 것이다.
같은 트랜잭션 안에서 SELECT 쿼리를 실행했을 때는 항상 같은 결과를 가져와야 한다는 REPEATABLE READ 에 어긋난다.
REPEATABLE READ
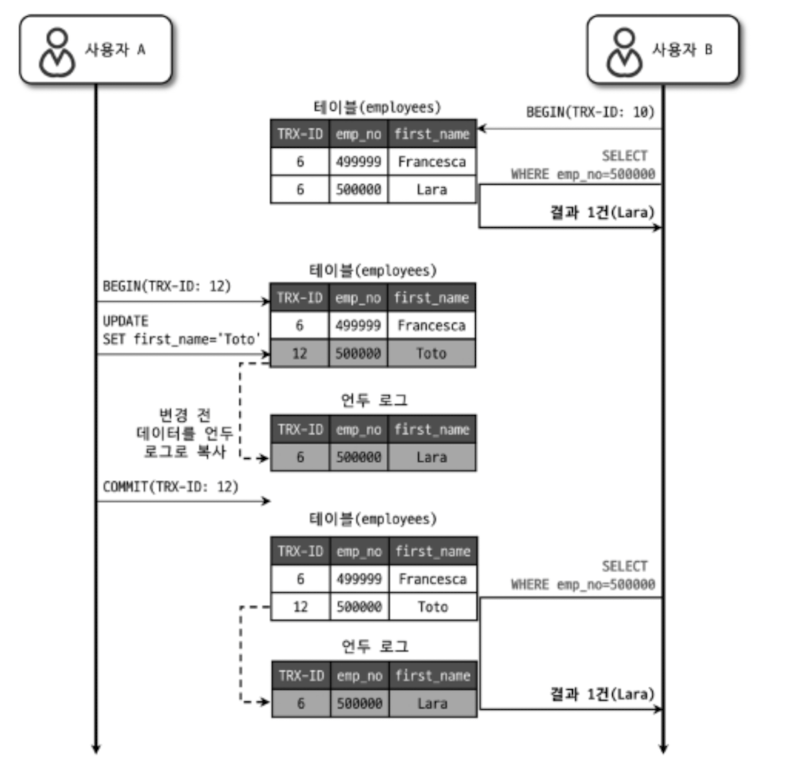
REPEATABLE READ 격리 수준에서는 트랜잭션 번호를 통해 NON-REPEATABLE READ 를 해결한다.
언두 영역에 백업된 레코드에는 변경을 발생시킨 트랜잭션의 번호가 포함돼 있다.
위 그림 예시를 통해 살펴보자
- 사용자 B 는 트랜잭션을 시작하고 500000번 레코드를 조회했을 때 1개의 결과 (Lara) 가 나왔다 (10번 트랜잭션 사용)
- 사용자 A 가 Lara -> Toto 업데이트한다. (12번 트랜잭션 사용)
- 변경 전 데이터를 언두 로그에 복사하는데 이때 그 전 트랜잭션 번호도 함께 복사되어 있다.
- 사용자 B 가 다시 같은 쿼리로 조회해도 같은 결과 (Lara) 가 나온다.
- 사용자 B 트랜잭션 (10번) 은 자신보다 낮은 트랜잭션 번호에서 변경한 것만 보게된다.
주의점 : 하나의 레코드에 대해 백업이 하나 이상 존재할 수 있기 때문에 트랜잭션을 시작하고 장시간 트랜잭션을 종료하지 않는다면 언두 영역이 무한정 커져 성능을 떨어트릴 수 있다.
하지만 REPEATABLE READ 격리 수준에서도 아래와 같은 부정합이 발생할 수 있다. (PHANTOM READ)
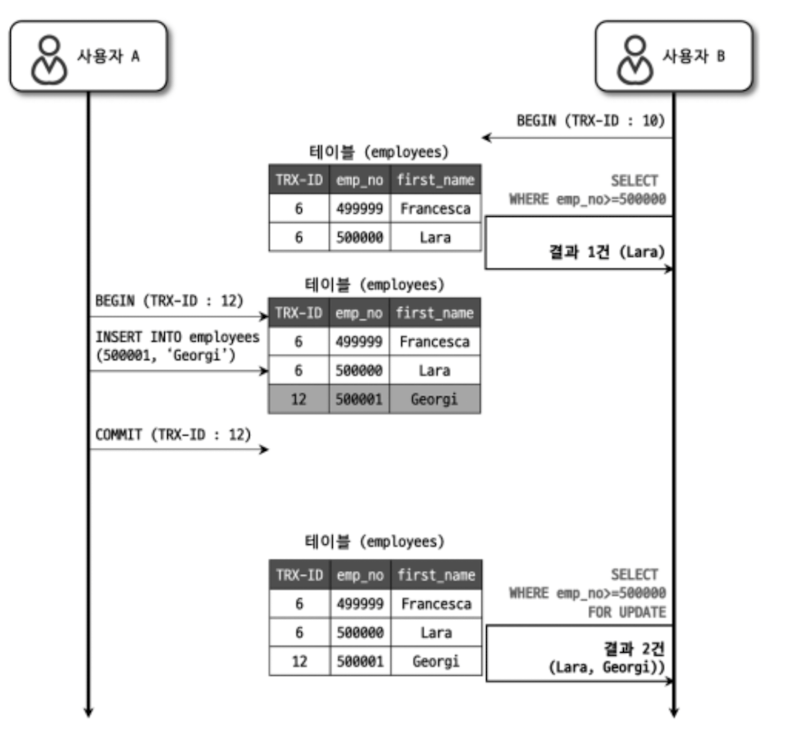
그림을 보면 사용자 B 의 트랜잭션 중간에 사용자 A 가 새로운 레코드를 추가하여 같은 트랜잭션의 동일한 SELECT 쿼리 결과가 달라졌다.
이렇게 다른 트랜잭션에서 수행한 변경 작업에 의해 레코다가 보였다 안 보였다 하는 현상을 PHANTOM READ 라고 한다.
SERIALIZABLE
가장 단순한 격리 수준이며 가장 엄격한 격리 수준이다.
트랜잭션의 격리 수준이 SERIALIZABLE 로 설정되면 읽기 작업도 Lock을 획득해야만 한다.
한 트랜잭션에서 읽고 쓰는 레코드를 다른 트랜잭션에서 절대 접근할 수 없다.
따라서 PHANTOM READ 문제도 발생하지 않지만 동시 처리 성능이 너무 떨어진다.
InnoDB 스토리지 엔진에서는 갭 랍과 넥스트 키 락 덕분에 REPEATABLE READ 격리 수준에서도 PHANTOM READ 문제가 생기지 않기 때문에 굳이 SERIALIZABLE 격리 수준을 사용하지 않는다.